1. B树
1.1 B树的定义
这里的B树,也就是英文中的B-Tree,一个 m 阶的B树满足以下条件:
1.每个结点至多拥有m棵子树;
2.根结点至少拥有两颗子树(存在子树的情况下),根结点至少有一个关键字;
3.除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
4.所有的叶结点都在同一层上,B树的叶子结点可以看成是一种外部节点,不包含任何信息;
5.有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
6.关键字数量需要满足ceil(m/2)-1 <= n <= m-1;
1.2 B树图例(M=3)

B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
1.3 B树的特性
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
最低搜索性能:O[Log2(N)];其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
2. B+树
2.1 B+树的定义
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
2.2 B+树图例(M=3)
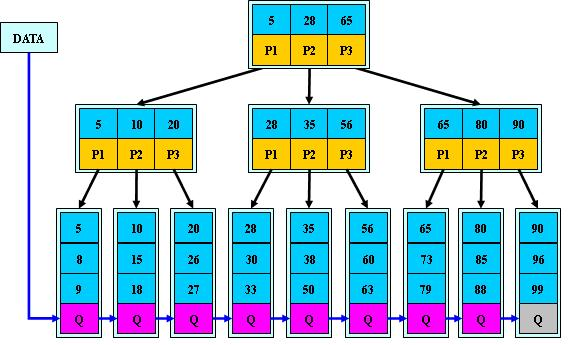
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
2.3 B+树的特性
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
3. B树与B+树的比较
3.1 为什么B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
1.B+tree的磁盘读写代价更低:
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+tree的查询效率更加稳定:
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3.B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。
B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
3.2 数据库选用B+树的原因
1.B+树有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
2.mysql 底层存储是用B+树实现的,因为在内存中B+树是没有优势的,但是一到磁盘,B+树的威力就出来了。
B+树是B树的变形,它把所有的附属数据都放在叶子结点中,只将关键字和子女指针保存于内结点,内结点完全是索引的功能,最大化了内结点的分支因子。不过是n个关键字对应着n个子女,子女中含有父辈的结点信息,叶子结点包含所有信息(内结点包含在叶子结点中,内结点没有指向“附属数据”的指针必须索引到叶子结点)。这样的话还有一个好处就是对于每个结点所需的索引次数都是相等的,保证了稳定性。
3.3 B/B+Tree索引的性能对比
我们使用磁盘I/O次数评价索引结构的优劣。先从B Tree分析,根据B Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现中B-Tree在每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。 综上所述,用B-Tree作为索引结构效率是非常高的。而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。 B+Tree更适合外存索引,原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小,由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。